using a linear regression method, evaluating the global and local spatial autocorrelation of the modeling residuals, and comparing this spatialization to results from deterministic interpolation and geostatistical interpolation methods.
Using spatialization and geostatistics methods to study the hot extremes of daily maximum temperatures in a region of metropolitan France,Bourgogne-Franche-Comté.Spatialize projections relating to hot extremes maximum daily temperatures for the month of July by 2100 using a linear regression method, evaluating the global and local spatial autocorrelation of the modeling residuals, and comparing this spatialization to results from deterministic interpolation and geostatistical interpolation methods.
Dossier Spatialisation Géostatistiques
Analyse Spatiale
Rik Karier et Ahmed Sanusi
UNIVERSITÉ DE STRASBOURG (FERN)
https://doi.org/10.13140/RG.2.2.25390.42560
Dossier Spatialisation-Géostatistiques
Introduction :
Le réchauffement climatique est probablement le phénomène qui menace l’humanité le plus. Ainsi, il est intéressant et important de projeter les températures futures dans des modèles pour éventuellement prendre des mesures pour atténuer les effets de ces températures élevées. Pour réaliser des telles cartes, nous nous sommes basés sur les données de Aladin Climat.
Toutes les cartes représentent les températures du mois de juillet en 2100 (horizon 3). De plus, les données exploitées sont issues du scénario RCP 8.5, c’est le scénario le plus grave pour le climat mondial. Pour modéliser ces informations, on a utilisé la méthode de l’interpolation par l’inverse de la distance (IDW), différents types de krigeage et un modèle de régression linéaire.
D’abord, nous allons présenter les cartes qu’on a réalisé. Ensuite, on va comparer les tableaux d’erreurs de modèle de régression linéaire au IDW et au krigeage. Par la suite, on va analyser l’autocorrélation spatiale. Puis, on va expliquer la méthodologie qu’on a employé pour réaliser les cartes. Finalement, on va faire une analyse statistique et spatiale de nos résultats obtenus.
1. Cartographies des moyennes températures maximales journalières en juillet en 2100
1.1
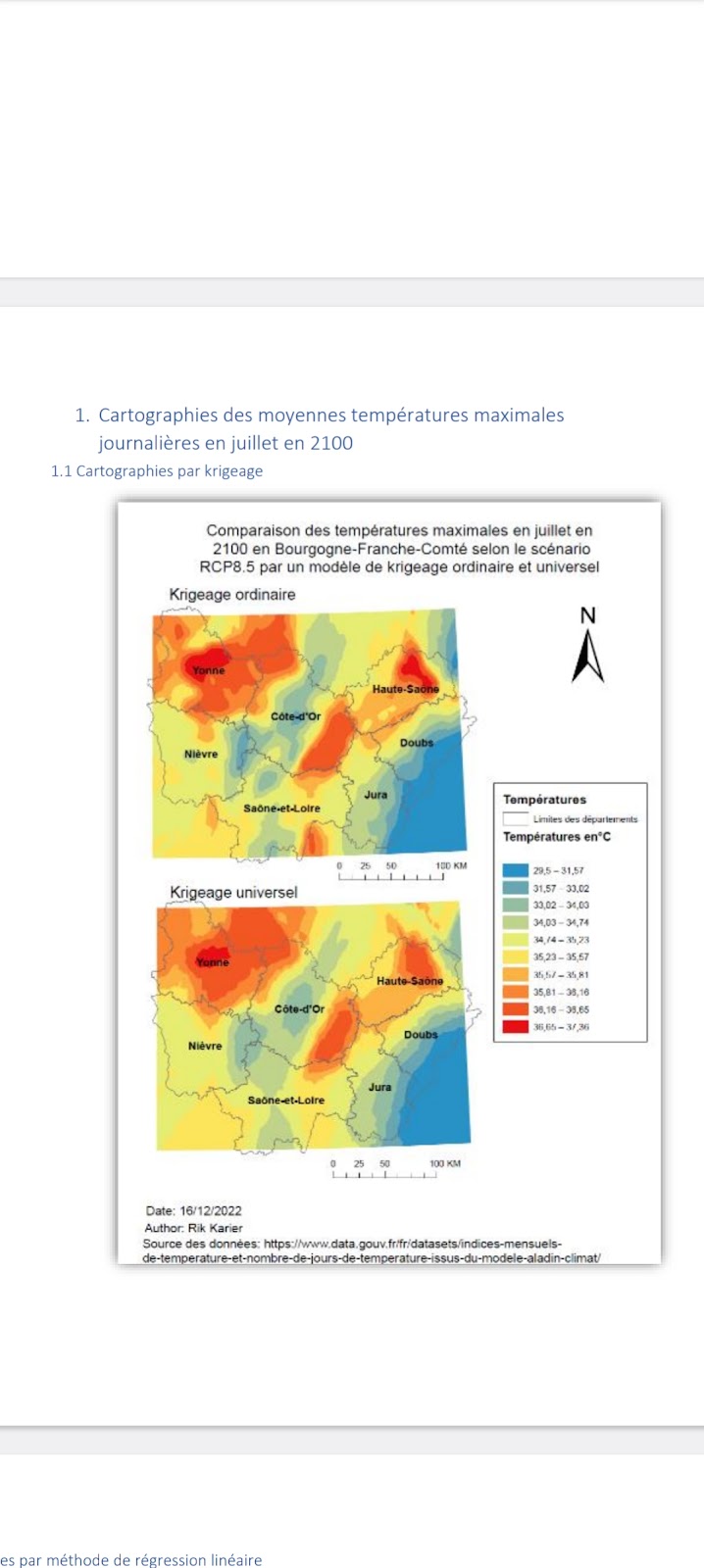
Cartographies par krigeage
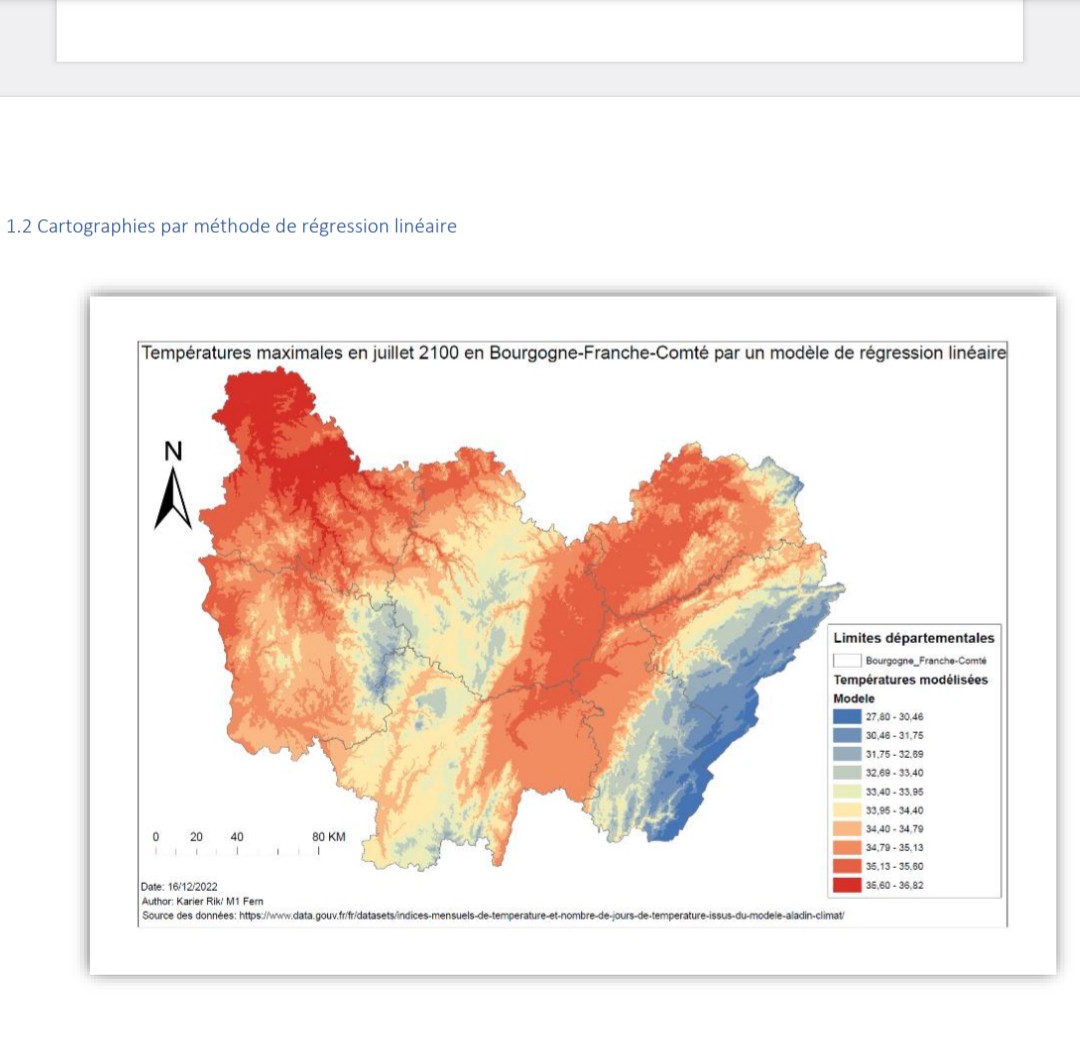
1.2 Cartographies par méthode de régression linéaire
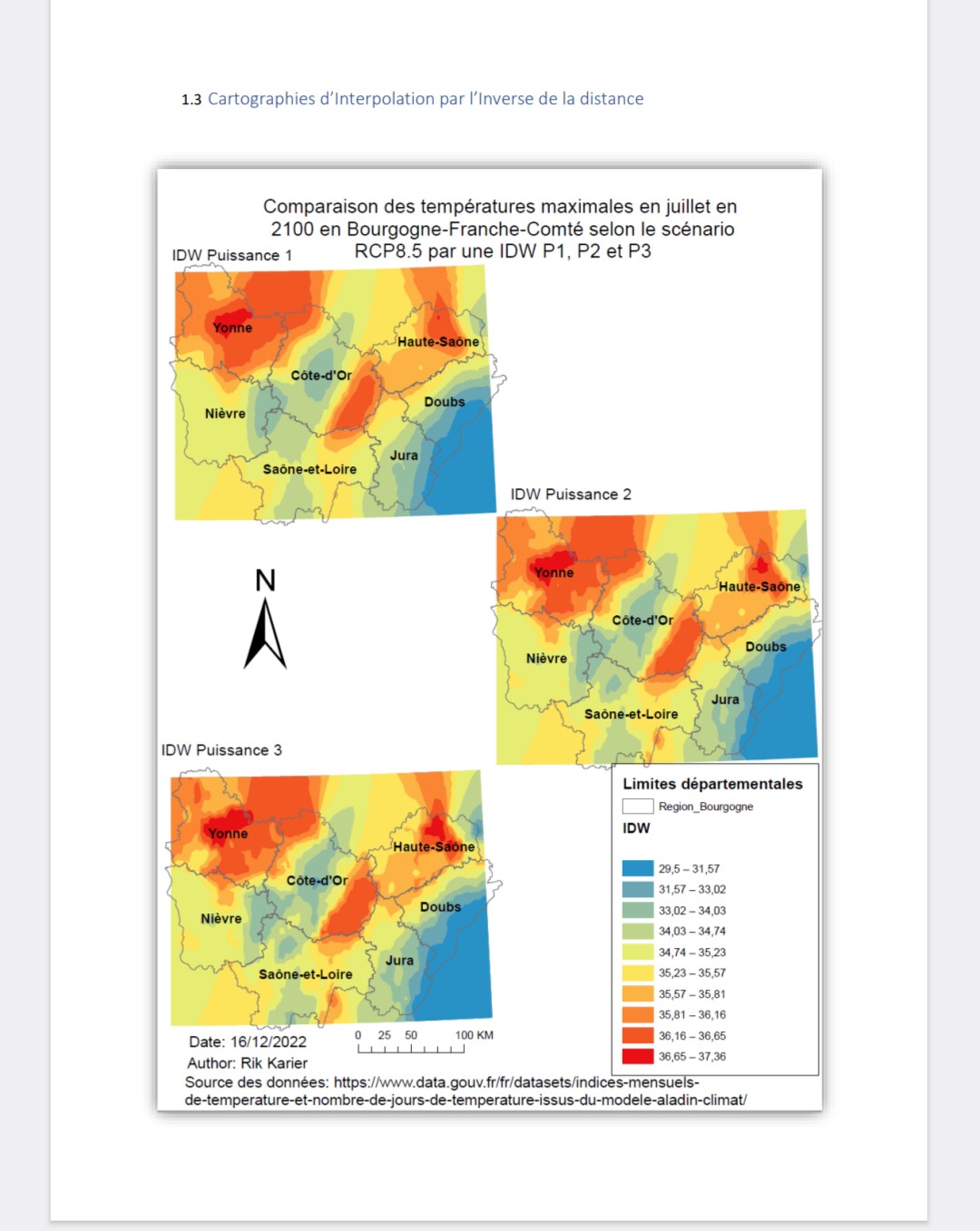
1.3 Cartographies d’Interpolation par l’Inverse de la distance
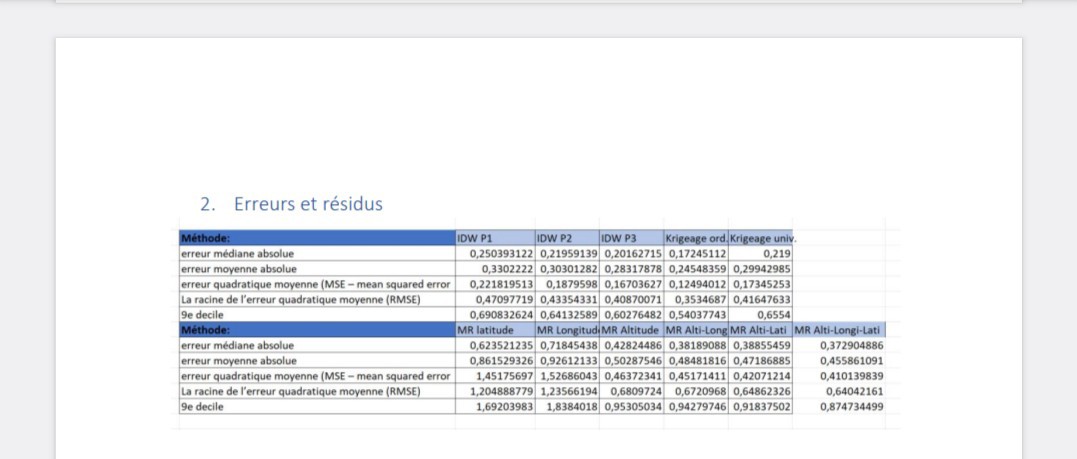
2. Erreurs et résidus
3.Analyse de l’autocorrélation globale et locale des résidus du modèle de régression linéaire
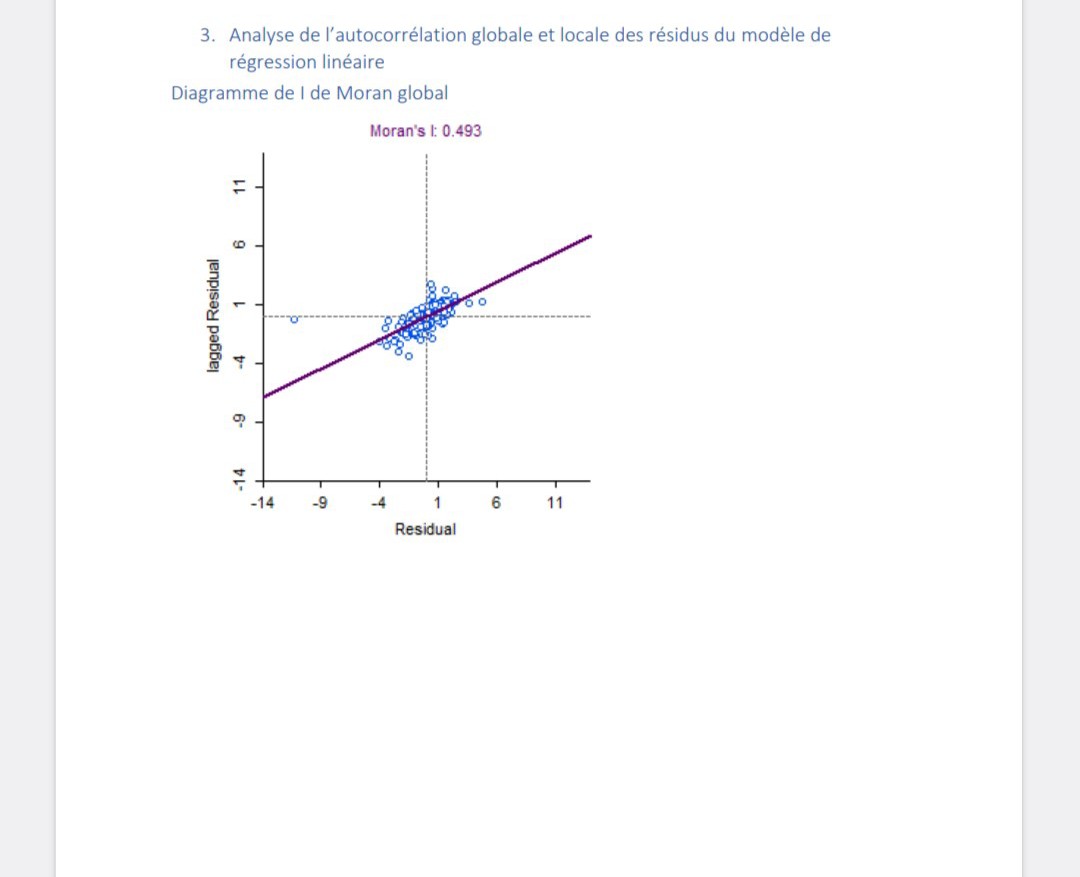
Ci-dessus, il y a le diagramme de Moran et les cartes d’autocorrélation de Lisa qui représentent les pvalues ainsi que la carte des clusters.

Le diagramme représente l’autocorrélation spatiale des résidus du modèle. C’est l’écart entre les températures mesurées et estimées. L’autocorrélation est exprimé par le I de Moran. Cet indicateur est de 0,493. Cela nous laisse dire qu’il existe une structure spatiale marquée et positive.
La carte des p-values montre le dégrée de similitude des valeurs observées et leur valeurs voisines. Les résidus négatifs et donc les valeurs sous-estimées et plus basses se situent majoritairement dans les montagnes du Jura, le département de la Côte d’Or, Haute Saône et du Doubs.
La carte des clusters montre la distribution de l’indice I de Moran dans notre territoire étudié, la Bourgogne-Franche Comté. On remarque que de nouveau le Jura ressort. À côté, il y a encore certaines zones qui ressortent parallèlement au Jura vers le NW. Les zones en rouge foncé et en rose correspondent aux zones avec des résidus positifs. Le rouge foncé (HIGH-HIGH) est majoritairement situé dans les plaines ou les températures peuvent être plus élevé qu’en altitude. C’est-à-dire l’autocorrélation est positive, donc les valeurs voisines sont similaires. Les valeurs représentées en bleu foncé sont classifiées sous LOW-LOW. Ce sont donc des températures basses dans un contexte de températures basses. Ce sont les régions avec moins de chaleur en mois de juillet 2100.
Les valeurs en rose et en bleu claire (HIGH-LOW et LOW-HIGH) correspondent aux résidus élevés dans un contexte de températures faibles respectivement à des valeurs basses dans un contexte de valeurs hautes. Ces 2 catégories sont très peu réparties sur la carte.
Une grande partie des valeurs n’est pas significative dans leur contexte de valeurs.
4. Synthèse méthodologique récapitulant la démarche suivie
Justification des étapes suivies
IDW et Krigeage
Tout d’abord, nous avons téléchargé et préparé le fichier des températures issu de Aladin-Climat. Il faut supprimer le texte en tête du document pour qu’Arc Map peut le traiter. Ensuite, nous avons ajouté le fichier texte des températures sur Arc Map avec la fonctionnalité «Add Data ». Par la suite, il faut changer le système de projection de « WGS84 » vers « RGF 1993 Lambert-93 ». La prochaine étape consiste en exportation des données de températures sous format « shapefile ». I faut vérifier si les données sont bien projeté dans le système de coordonnée « Lambert-93 ». Après cette étape on a ajouté le fichier shapefile des départements de France.
Vu que l’horizon lointain (H3- année 2100) nous intéresse. Il faut sélectionner le H3 par une « sélection par attributs» dans la table attributaire. De nouveau on a exporté la couche qui contient seulement les données « H3 ».
Nous devons représenter les températures de 2100 dans la Bourgogne-Franche-Comté donc il faut qu’on « découpe » « clip » les départements qui font partie de cette région.
Pour commencer à faire notre interpolation par l’inverse de la distance (IDW), il faut activer le « Geostatistical Analyst ». Cette fenêtre nous permettait d’utiliser le « Geostatistical Wizard ». Nous avons basé notre IDW sur le fichier « H3_Bourgogne » et le champ de la table attributaire qui contient les données du mois de juillet en 2100 selon le scénarion RCP 8.5. C’est le champs «NORTXQ90_D». On a fait des essais sur la puissance (P1, P2 et P3). Les nombre de voisins on n’a pas changé, il est resté à un minimum de 10 et un maximum de 15 voisins. Dans une dernière étape nous avons exporté le « Cross Validation Result »
On a utilisé les essaies de puissance 1, 2 et 3 parce que le plus souvent on utilise la puissance 2 parce qu’elles donnent les résultats les plus pertinents. Si on utilise plus de puissance alors les valeurs en proximité sont plus influent et la surface montre plus de détails (il y a des limites plus abruptes). Si on donne une puissance inférieure à 2 alors les plus qui sont plus éloignées ont plus d’influence. Ainsi la carte faite avec une carte de puissance 2 est la plus pertinente parce qu’elle donne l’optimum entre trop peu et trop de détail.
Pour faire le Krigeage on a utilisé de nouveau le « Geostatistical Wizard ». Cette fois on a utilisé de nouveau les mêmes variables comme pour le IDW. Nous avons décidé de faire une carte sur la base d’un krigeage ordinaire et une sur un krigeage universel. Le RMSE du krigeage ordinaire est de 0,353. Le krigeage universel a un RMSE de 0,416. Cela signifie que le Krigeage ordinaire semble d’être mieux adapté parce que cette valeur est plus basse. Nous avions aussi analysé le krigeage universel parce que cette méthode est souvent utilisée pour des données avec une tendance.
La méthode de régression linéaire
On a commencé avec la même démarche comme dans les 3 premiers paragraphes de l’IDW. Ensuite, on a créé notre maillage de 500m de côté par la fonctionnalité « create fishnet ». Par la suite il a fallu découper la maille aux limites de la Bourgogne-Franche-Comté. Puis, on a importé les données altitudinales pour les découper sur nos limites. Ce fichier raster a dû être converti en format vecteur qu’il soit utile par la suite. Cela permet que les données soient représentées de manière ponctuelle et non pas surfacique.
La prochaine étape va joindre les données altitudinales au maillage et on garde les champs utiles dans la table attributaire. De plus, on ajoute la latitude et la longitude et on les a calculés avec « calculer la géométrie ». De plus, on a ajouté le champ « ID unique » où on ajoute les données du champ FID. Finalement la fonctionnalité de « Ordinary least square » a permis de sortir des fichiers de rapport qui sont important pour l’interprétation et pour calculer les indicateurs d’erreurs.
Les indicateurs d’erreur ont été calculé dans Excel.
Grâce à GeoDa on a pu analyser l’autocorrélation spatiale. Ce logiciel permet de calculer l’indice de Moran et de LISA. Les analysent sur GeoDa se sont fait avec un facteur queen 1.
4. Interprétation statistique et spatiale des résultats obtenus
Le modèle de régression linéaire présente un R^2 de 0,733 pour la variable de l’altitude. Cela veut dire que l’altitude explique 73% des résultats obtenues. La latitude, la longitude et l’altitude présentent ensemble un R^2 de 76,4 %. Donc, le modèle n’est pas vraiment parfait car il manque une ou des variables importantes. Le modèle est le plus pertinent en incluent les 3 facteurs cité.
Le krigeage ordinaire a des indicateurs d’erreur moins élevées que le krigeage ordinaire ce qui nous laisse dire que le krigeage ordinaire est mieux adapté pour représenter ces données car ce modèle est plus pertinent selon les indicateurs d’erreur.
Comme déjà décrit la puissance de 2 pour le l’IDW est le plus utilisé et aussi notre choix même si les indicateurs d’erreurs sont plus faible pour le IDW avec une puissance 3.
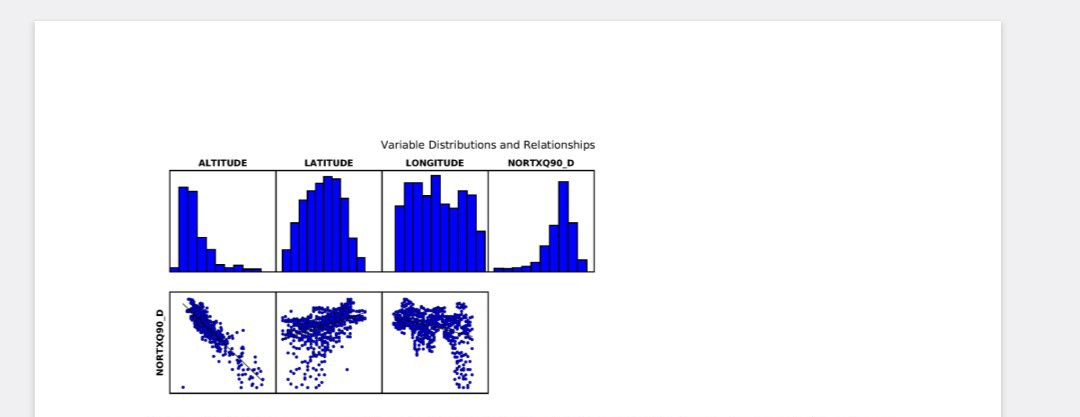
Si on consulte maintenant le rapport de l’ordinary least square sur la latitude, la longitude et l’altitude. On a vers la fin des graphiques (visible ci-dessous). On peut voir que les températures les plus basses dans l’est. Cette région correspond aux montagnes du Jura ce qui laisse nous déduire que la température diminue dans les hautes altitudes. Au centre dans la Saône et Loire et la Côte d’Or, il y a une zone avec des collines qui présente aussi des températures un peu plus basses ce qui est visible sur l’histogramme de la longitude. La hiérarchisation de la température par la latitude est un peu visible grâce à des zones de chaleur au Nord et 2 zones d’air plus frais au sud de la région d’étude. Mais l’histogramme de l’altitude est le plus marqué ce qui est souligné par un nuage de points assez dense et concentré. Comme l’altitude explique 73% du modèle, c’est le facteur le plus important de la variation de la température.
Figure 1:Carte topographique BFC
Source : https://www.actualitix.com/wpcontent/uploads/2017/04/carte-relief-bourgogne-franchecomte.jpg

La carte topographique à droite permet de visualiser la distribution de la topographie dans l’espace et donc aussi de faire un lien avec les cartes IDW, krigeage et par le modèle de régression linéaire pour comprendre les températures. C’est notamment important vu que l’altitude explique 76% des résultats.
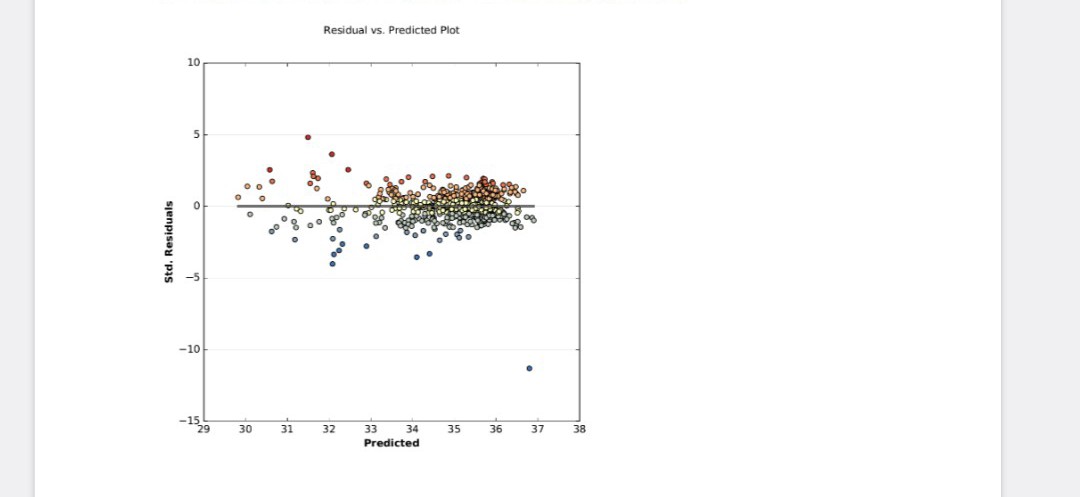
On peut observer sur le graphique ci-dessous (Residual vs Predicted Plot) que la plupart des valeurs est situé entre 33 et 36,5 dégrées. Il y a peu de valeurs avec une erreur importante sauf une seule à +5 et à -11. La grande majorité est situé entre + et – 3. Il n’y a aucune tendance des valeurs ce qui nous montre que le modèle est bon mais pas parfait vu que R^2 est que de 76%.
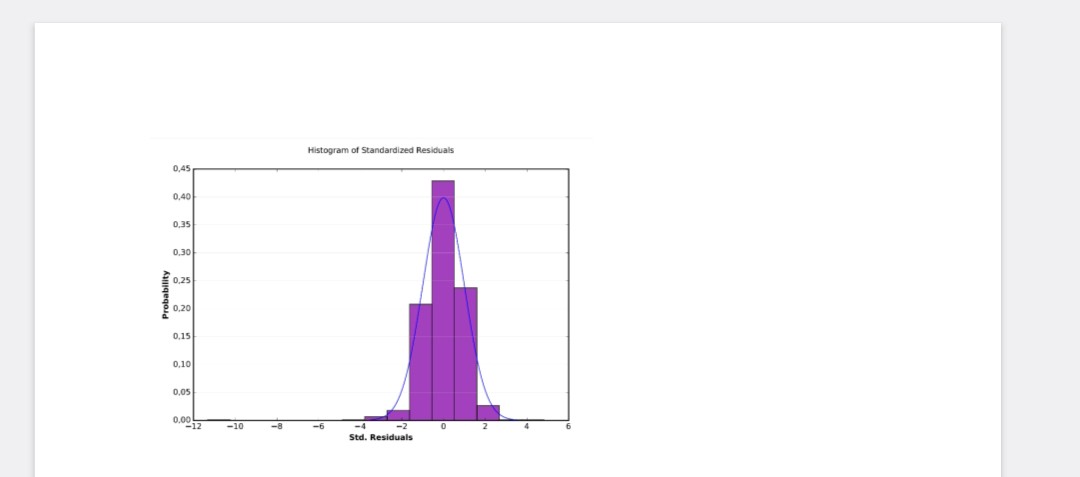
Puis, il y a l’histogramme des résidus standardisés qui a une répartition quasi parfaite. Les valeurs résiduelles à gauche et donc négatifs ont une probabilité d’un peu plus de 0,22 et celle à droite d’une probabilité de 0,25.
L’indice I de Moran est de 0,493 ce qui nous laisse conclure qu’il y a une autocorrélation mais elle n’est pas nette et très accentué.
Conclusion :
Pour conclure, on peut dire que les projections avec le IDW et le krigeage sont mieux adapté pour montrer les températures en 2100 que le modèle de régression linéaire. C’est notamment le tableau des erreurs qui donne des erreurs moins élevées pour les 2 premières méthodes. Néanmoins, il est intéressant d’analyser le modèle de régression linéaire parce qu’il donne certaines informations très intéressantes.
Il se peut que les températures fortes soient donc surestimées et inverse pour les valeurs faibles. C’est notamment due au fait qu’un grand nombre des résidus est non-significatif.
Les températures en Bourgogne-Franche-Comté sont fortement corrélé à l’altitude. Càd. Ils varient fortement avec l’influence de l’altitude. Il y a une opposition entre le Jura ou les collines et les plaines. Par contre la température varie peu en fonction de la latitude ou de la longitude.



Comments
Post a Comment